
Duplicate content is a much-discussed topic in SEO, from tales of Google’s alleged penalties to questions about the best strategies for avoiding and managing it. Whilst it can certainly have consequences for SEO performance, in truth, it’s often not half as bad as people may think when handled appropriately. Let’s be clear there is no such thing as a Duplicate content penalty! And, sometimes ‘managing duplicate content’ means simply leaving it alone. In other words, it won’t always impact your rankings and some duplicate issues should simply be ignored.
In this blog, we will discuss the true impact of duplicate content on SEO performance and explore why it occurs. We will outline best practices for managing and resolving duplicate content issues to help maintain a strong online presence and ensure your website provides unique and valuable information to your audience. And, we’ll give you some examples when you don’t really need to do anything at all – showing you that Google is much smarter these days.
Let’s dive in!
In this post:
What is Duplicate Content?
First things first, what is duplicate content?
Duplicate content refers to content that is identical or highly similar and appears in more than one place online. This can happen when content is published on multiple websites or when different pages on the same website contain the same or very similar content due to direct copying or scraping.
When it occurs across different pages on your own website, it is known as internal duplicates, and when on other websites, it is known as cross-domain duplicates.
To qualify as duplicate, a piece of content must exhibit the following traits:
- Significant similarity in language, organisation, and layout to other content.
- Minimal to no new information.
- Lacks extra benefits for the reader compared to a comparable page.
What is the Impact of Duplicate Content on SEO Performance
In general, cross-domain duplicates are usually a bit more “dangerous” and can result in a penalty. But that’s not a ‘duplicate content penalty’. It could be a number of different penalties. For example, if you own a site that creates pages upon pages of content that is actually scraped from other websites you might get hit by a Major Spam penalty.
It’s a common misconception that internal duplicate content can incur a ‘duplicate content penalty’ However, as explained by Google:
“Duplicate content on a site is not grounds for action on that site unless it appears that the intent of the duplicate content is to be deceptive and manipulate search engine results.”
Which begs the question, if there’s no penalty, why is duplicate content an issue for SEO?
Well, because whilst you may not receive the mystical penalty, it could still:
- Negatively impact your rankings
- Damage your site crawlability
- Dilute backlinks and reduce link equity
Let’s explore each of these in more detail.
Negatively impact your rankings
Google strives to provide users with the most relevant and useful content. For example, if multiple pages on your website have the same or very similar content, and Google can’t distinguish the ‘most helpful’, the Ranking system tries to determine the original source and position it within the SERP. And so here lies the problem.
If Google isn’t able to determine the original source, it can impact your rankings, and it may result in the content not ranking at all.
And if one of the versions does still manage to rank, it may not be the version you want to rank which as you can imagine, is pretty frustrating and means the user isn’t seeing the content you want them to.
Damage your site crawlability
As we know, to rank our content, search engines must first crawl and index the pages.
While the issue of wasting crawl budget doesn’t really come into play with most websites, having duplicate content might needlessly make the process inefficient. Google and other search engines will only spend so long on your site at a time. This means that the crawlers are less likely to get to the other content you want them to see, potentially reducing your visibility in the SERPs.
Dilute backlinks
A backlink is another site linking to your website. They can be great for SEO performance since they ultimately signal to search engines that your website is a useful, credible source.
In a Google Search Central SEO hangout recorded on September 17, 2021, John Mueller discussed how Google determines link equity. While Google’s algorithm has improved considerably since the days of PageRank, he explained that a good example for understanding how link equity works is by thinking about PageRank.

Source: Search Engine Journal.
However, if you have the same content spread across multiple pages, you risk receiving backlinks to the same content but for different pages. And you guessed it, the more duplicated content you have, the worse it gets. Every time another backlink is given to another page for THE SAME content, you’re losing valuable link equity, which could have all been pointing to one page.
The end result is potentially fewer SERP rankings, as you lose out on the potential topical authority you could have gained.
Common Causes of Duplicate Content
When we think of duplicate content, people often assume we are referring to directly copying or scraping content from other pages or competitor sites. In truth, when dealing with accidental duplicate content, this often isn’t the case.
Duplicate content can be caused by a number of different factors, including URL parameters and website structural issues. Some of the most common causes of accidental duplicate content are:
- Poor management of WWW and Non-WWW Variations
- Granting access with both HTTP and HTTPs
- Session IDs
- Incorrect Content Syndication
- Using copied or scraped content
Poor Management of WWW. and Non-WWW. variations
Users can often access your website using both via both www. and without www. For example, www.yourwebsite.com and yourwebsite.com.
If the site is accessible via both versions and you don’t manage this correctly, it can result in duplicated content issues as search engines, such as Google, will deem these URL variations to be two separate domains.
Granting access with both HTTP and HTTPs
Similarly, allowing users access to your website through both HTTP and HTTPS can cause duplicate content issues.
Imagine HTTP and HTTPs as two sets of keys to the same house, one for a secure, upgraded entrance (HTTPs) and one for an old, less secure entrance (HTTP). Now, picture visitors arriving with keys to both gates. If they use both gates interchangeably, it can create confusion and inefficiency.
In the same way, when your website is accessible via HTTP (http://yourwebsite.com) and HTTPS (https://yourwebsite.com), search engines can get confused. They may perceive these two paths as two separate versions of your site with identical content.
This duplication can dilute your search engine ranking and cause issues with your site’s visibility.
Added query parameters
A similar issue, if not handled correctly, can be found in pages that have added query parameters added to them. You’ll recognise those if there is a /#/? added to the end of your url. This can be done purposefully by a developer or it can be done automatically by the CMS you are using.
Let’s look at two examples that are quite common, particularly in e-commerce.
- Session IDs
- Sorting /filtering parameters
Session IDs
Session IDs attached to the URL. This happens quite often with e-commerce websites that use session IDs to track users who have placed items into their shopping baskets.
For example, a URL could be something like www.yourwebsite.com/shoes?sessionID=123, where the ?session=ID=123 is the appended query parameter.
While this allows us to track users, what happens when another user accesses that URL? You guessed it, another URL is created with a different session ID.
This can cause duplicate content issues because search engines may index each URL as a separate page, even though the content is identical.
It also makes it harder for search engines to determine which version of the page to prioritise in search results.
Sorting/filtering parameters
Another quite common issue are parameters that are the results of filtering or sorting. Let’s say your www.yourwebsite.com/shoes page has a filter that let’s you sort shoes based on colour. Your URL when the filter is used might become something like www.yourwebsite.com/shoes?colour-pink
Those filters might not be recognised by search engines and the URLs could be treated as separate, even though the have they same content. Causing duplicate content issues!
Incorrect Content Syndication
Incorrect content syndication can lead to duplicate content issues when content is published on multiple websites without proper attribution or canonicalisation. This situation arises when the same content is shared or republished across different sites, causing search engines to encounter identical or highly similar content in multiple locations.
For example, let’s say you own a blog called “Tech Insights” with the domain techinsights.com. You write a detailed article about the latest trends in artificial intelligence. The article has gained popularity, and other websites want to republish it. So, you allow two other websites, techworld.com and aiinnovators.net, to republish your article.
However, instead of linking back to your original article and including a canonical tag to your original URL, both websites simply copy and paste your article in full on their own pages (techworld.com/ai-trends and aiinnovators.net/ai-trends), without proper attribution or canonicalisation. More on this later!
Copied or Scraped Content
Another cause of duplicate content is copied or scraped content. This is usually where another site reuses content from another website without prior permission or proper attribution.
The good news is that you shouldn’t worry too much about the impact on your site if you notice others scraping or copying content from yours. Google has previously published how they deal with scraped content, explaining that they are pretty confident in their ability to determine the original source.
You also shouldn’t panic about accidentally creating similar content to another site within your topic area. We know that when you’re writing about a particular topic, there are only so many ways to say the same thing. Particularly if it’s a niche subject!
In these cases, it’s just important to ensure you’re not physically just copying and repurposing other people’s content. As explored by Sean and Emina in Episode 12 of SEOs Getting Coffee on Competitor Analysis, the main thing is to ensure that you’re always ‘doing it better’ and adding additional value for the end user.
As mentioned what you should worry about is if your website is a den of spam such as tons of scraped pages created for the purposes of ranking. In that case, you are risking a Spam penalty. These types of black hat tactics might work for a bit but then crash and burn very quickly!
How to Identify Duplicate Content
There are many different tools and platforms that you can use to monitor and identify duplicate content issues or potential problems. From free to paid platforms, we’ll explore some of the top tools for keeping on top of things and walk through how to do so on each platform.
- Google Search Console.
- Screaming Frog – SEO Spider
- Semrush.
Let’s explore each further below.
Google Search Console
Google Search Console is a free, user-friendly tool designed to assist website owners in gauging their performance on Google Search and identifying ways to enhance their visibility to attract more relevant traffic to their sites.
Within Google Console, you can see which of your pages are indexed and which aren’t. To see this, simply click Pages under Indexing on the left-hand toolbar.
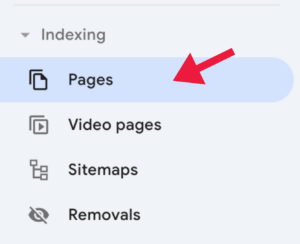
You will then see a selection of reasons why pages are not being indexed, two of which are due to duplicate content.
- Duplicate without user-selected canonical
- Duplicate, Google chose a different canonical than the user
For the sake of this example, let’s take a look at Google choosing a different canonical to the user.
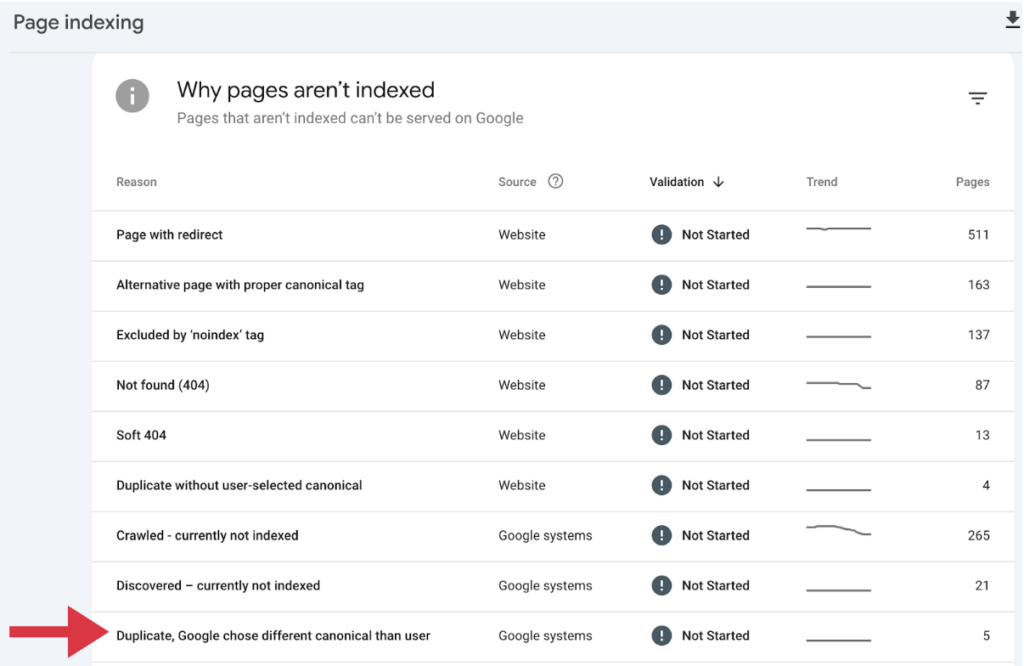
Here, we can see an example of Google identifying and applying a new canonical based on its own interpretation of the original page.
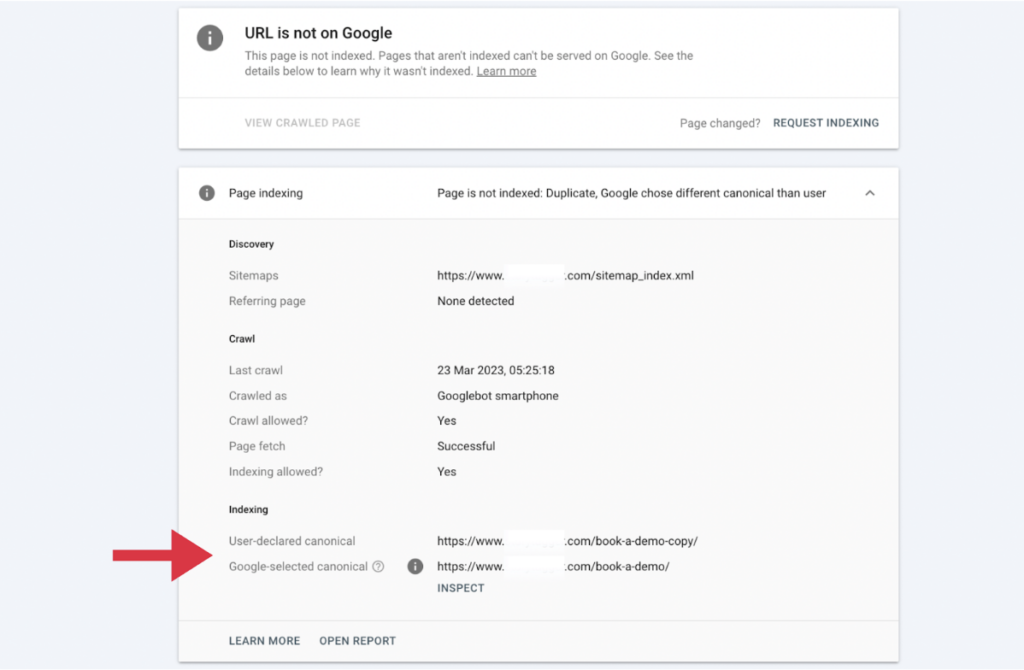
The URLs clearly show that someone has created a copy of the original Book a Demo page with a self-referencing canonical in the header. This tells Google that the website owner would like this page to be identified as the original.
The likelihood is that this was created and forgotten about, and as a result, it is now appearing on the sitemap.
As explained by Google’s webmasters, Google is usually smart enough to know that this is the case; therefore, it applies the correct original page as the canonical.
As a result, no action really needs to be taken here. However, if you really want to Dot Your Is and Cross Your Ts, you could go to the copied page, update the user-declared canonical to the original Book a Demo page, and then apply a 301 redirect from book-a-demo-copy/ to book-a-demo/.
As we said, in reality, Google has it covered and no action really needs to be taken here. Situations such as this, demonstrate Google’s ability to correctly identify and resolve instances of duplicate content. Therefore, it highlights that duplicate content is not often the doom-impending issue that it’s so often positioned as being. By using tools such as Google Console to routinely monitor and stay on top of any ‘issues’, there’s no reason you should ever feel the negative effects of duplicate content.
Screaming Frog - SEO Spider
Screaming Frog SEO Spider is a brilliant site crawling tool widely used for conducting SEO audits on sites of all sizes. You can get started with SEO Spider for free, with an allowance of 500 URL crawls before you’re required to buy a licence. However, it’s important to note that some features will be limited. In our opinion, the licensed version is worth its weight in gold when it comes to carrying out SEO audits and monitoring site health.
Using SEO Spider, you can identify exact duplicates and near duplicates where there is some similarity between different pages on your site. To learn how to do so, check out this step-by-step guide and video tutorial from Screaming Frog themselves.
Semrush
Semrush is another great SEO tool that can be used for various tasks, such as keyword research, competitive analysis, site audits, backlink tracking, and comprehensive online visibility insights.
It also provides a comprehensive analysis of any duplicate content. To access this, you’ll first need to create a project for your site and carry out your initial site audit. You run this by adding your domain URL to the search bar and hitting ‘start audit’.
Once complete, you’ll see your full performance dashboard, as below.
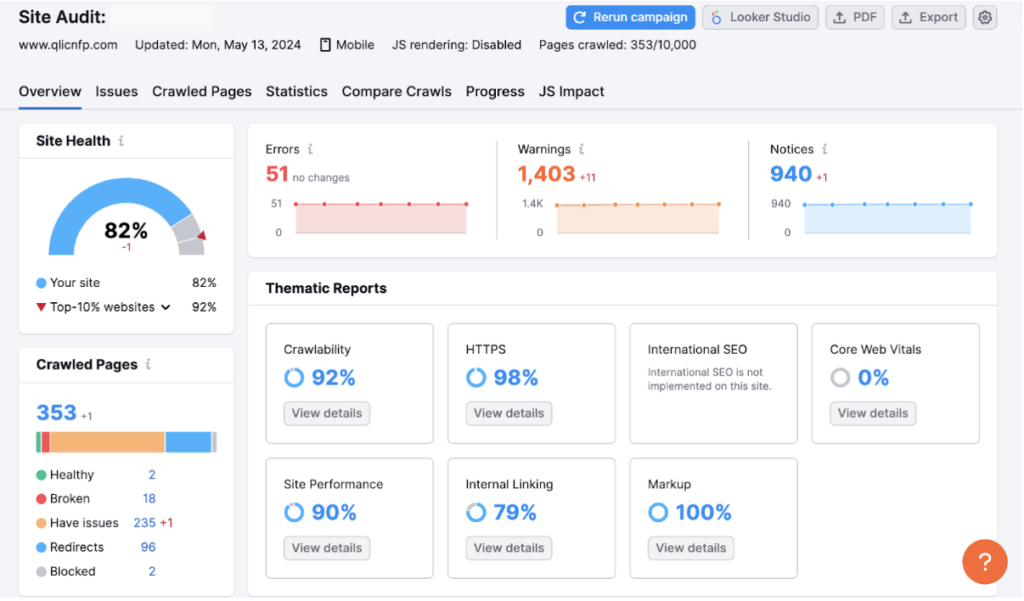
To review your duplicate content issues (if you have any), head over to issues.
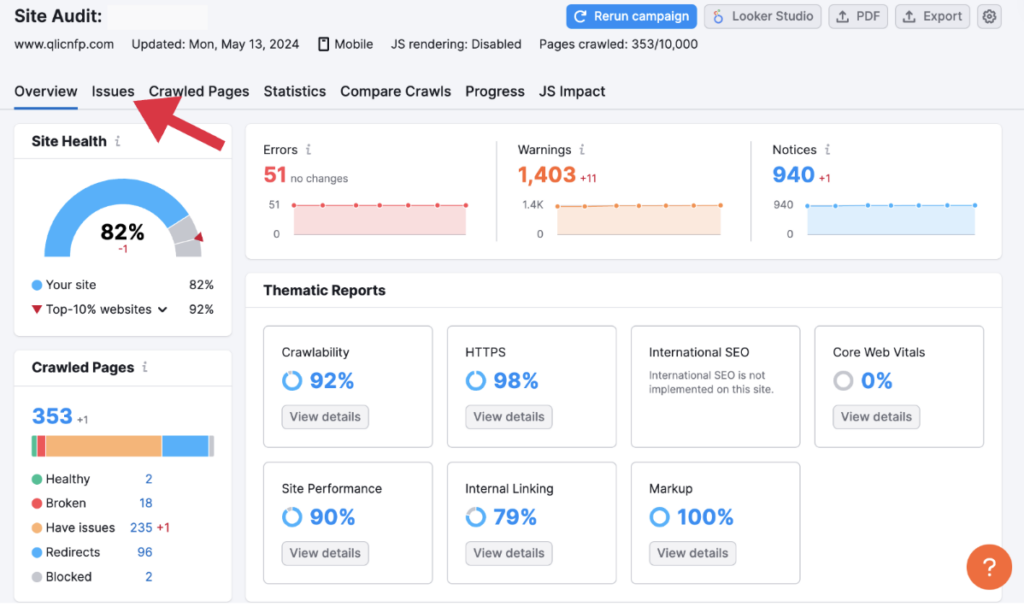
You can then review all notifications and if required, filter for ‘errors’ and ‘duplicates’.
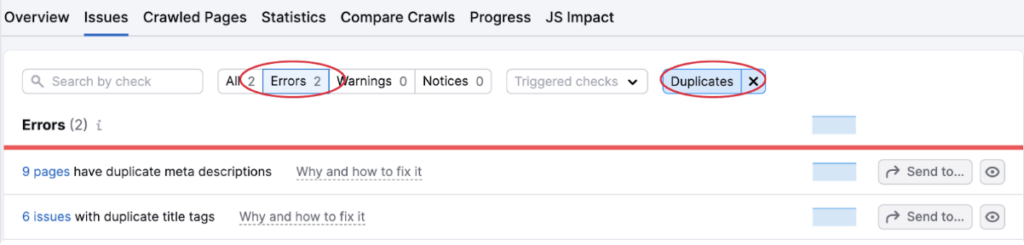
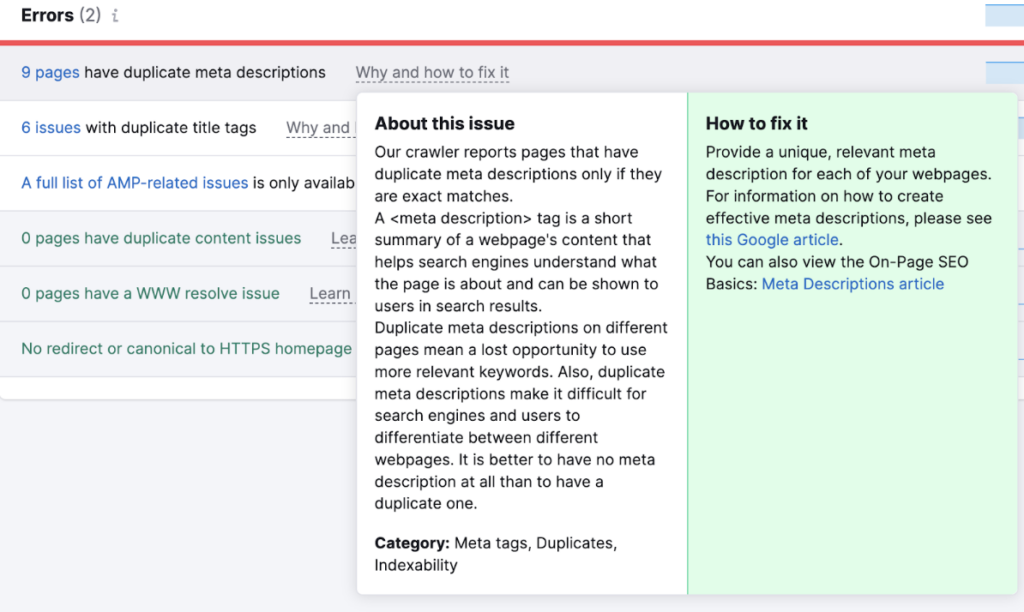
You can then also access an explanation of why this issue has occurred and how to fix it by hovering over ‘why and how to fix’.
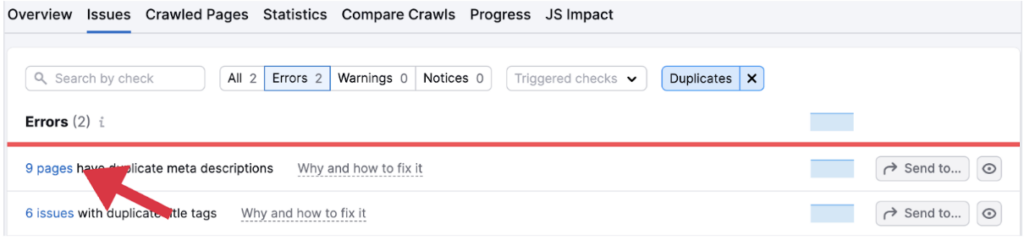
To examine exactly which pages are causing the error in depth, simply click on the linked pages and review where the duplicates are occurring.
Best Practices for Managing Duplicate Content
When it comes to avoiding and managing duplicate content, there are a few different methods to use. As with most things in SEO, the best approach will depend on the situation so in this section we will explore the options available and their appreciated use cases.
- Set up canonical tags
- Implement 301 redirects
- Use Noindex Meta Tag
- Consolidate Content
Set up canonical tags
A canonical tag is a snippet of html code shown as rel=”canonical” placed in the head section of the page code that is used to define the ‘primary’ or ‘original’ version when there are duplicate pages on your website.
The canonical tags also signal to search engines, like Google, which version they should rank and direct the authority and any link equity to.
In this case, your canonical tag will include an alternative URL pointing to the preferred ‘primary’ page. For example:
If we wanted our page www.vixendigital123.com to point to www.vixendigital.com as the canonical page, our tag would read: rel=”canonical” href=“www.vixendigital.com”
You can also use self-referencing canonical tags. Whilst, as explained by Google’s very own webmaster John Mueller, self-referencing canonical tags are not essential – it’s a great practice. By using them, you are telling Google that this is the original version of this content and it’s the one you want them to rank.
In practice, this means that each page on your site should have a canonical tag that points to its own URL (if it doesn’t need to be pointing to an alternative ‘primary’ URL).
See below:
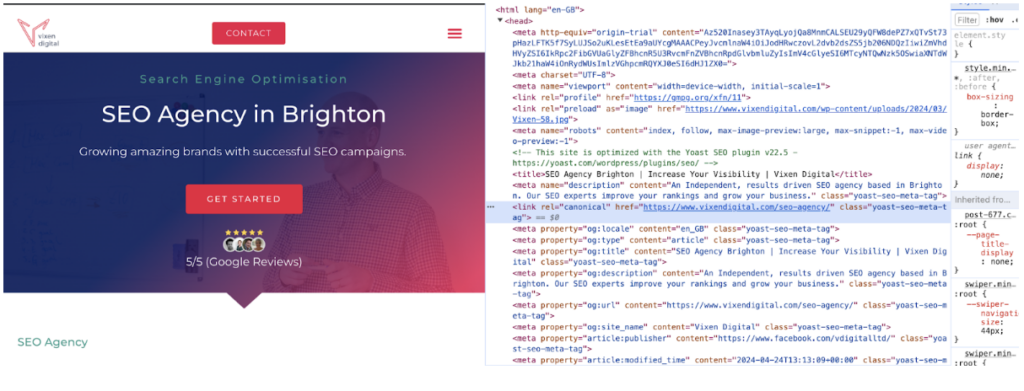
Google will determine the canonical URL in several different ways. However, the rel tag plays a key role in this selection, and using self-referencing canonical tells Google that this is the page you really want to be chosen as the canonical.
Implement 301 redirects
Using a 301 redirect enables you to permanently move from one URL to another. It’s a good option when you no longer need the old URL and do not want search engines to crawl, index, or rank this page. However, it’s a permanent solution and should only be used when you know that you are permanently moving to the new URL.
Make use of Noindex Meta Tag
The <meta name=”noindex”> tag is a HTML tag located in the <head> section of the code and is used to tell search engines not to index a specific page or section of a website, preventing it from appearing in SERP.
The tag can be used to avoid duplicate content by instructing search engines not to index pages that contain identical or nearly identical content to other pages on the same website. For example, things like your ‘get in touch’, ‘thank you’ or check out pages.
If using this method, you must ensure that crawling on the page is allowed in the robots.txt file. If you have stopped search engine crawling in your robots.txt the search engines won’t be able to see your noindex meta tag and your page may still be featured in the SERP if it’s been found via links on other pages.
Plus, Google recommends against using a robots.txt file to block duplicate content. If you do, it’s unable to assess content and will assume the page is unique, meaning the approach will not work.
Consolidate Content
Consolidating content can be a great option if it’s similar content causing your duplicate content issues. This is often the case for sites with a large collection of blogs written on similar topics that end up unintentionally overlapping over time. So, why not combine your similar pages into one killer page?
For example, let’s imagine you’ve written a number of useful resources on internal linking over the years. But, now things are beginning to overlap and cause duplicate content issues. Here’s how you could consolidate your content:
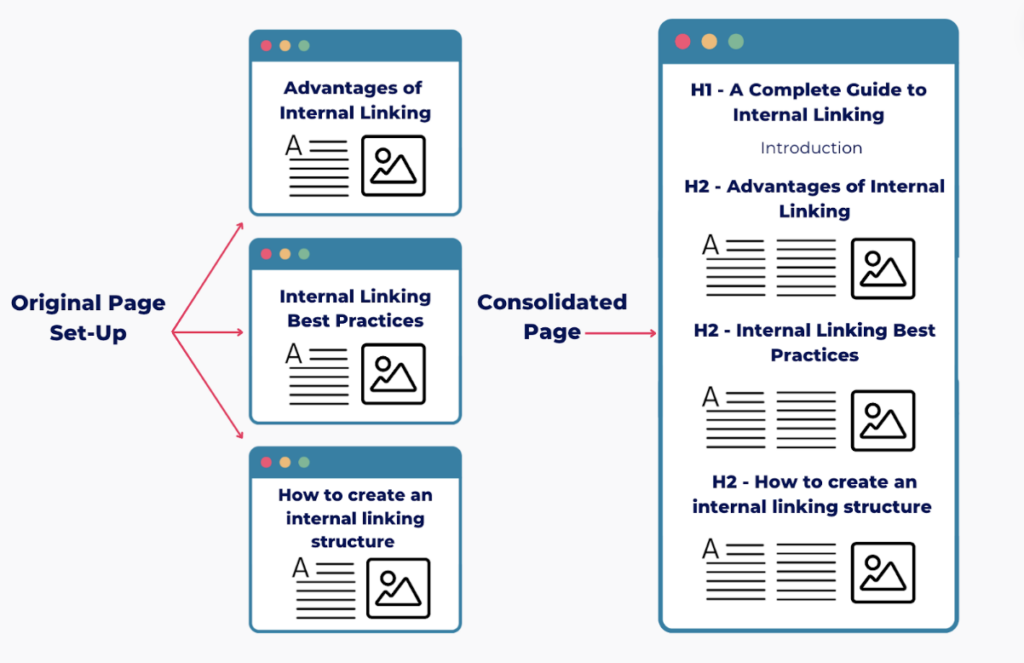
Combining and consolidating similar blog posts regularly can help avoid duplicate content issues. This practice can greatly enhance search engine ranking and optimise crawl budgets.
Remember! When consolidating, don’t create a whole new page. Instead, choose one of the existing URLs to move all of the content onto and set up a 301 redirect from your old URLs to the consolidated page.
Closing Thoughts on Duplicate Content in SEO
While duplicate content can challenge your website’s SEO, it doesn’t need to be a source of doom and gloom, as it is sometimes portrayed. By understanding its causes and effects, you can take simple yet effective measures to manage it. Or simply let it be!
Employing best practices such as canonical tags, 301 redirects, and the noindex meta tag can help you address and prevent duplicate content issues.
Additionally, consolidating similar content and keeping a consistent URL structure can improve your site’s performance by avoiding accidental duplicate content issues. Remember, duplicate content isn’t a significant threat when considered and managed appropriately. And, this also sometimes includes doing absolutely nothing and leaving those duplicate warnings be. Just don’t get tangled into solving things that are not actual issues and won’t make a big impact on your rankings.



